Welcome to my blog! Explore my posts and projects.
Understanding RAG from scratch (Part I)
1. Introduction to RAG Fundamentals Hey everyone, and welcome to our deep dive into Retrieval-Augmented Generation, or RAG! In the rapidly evolving world of Large Language Models (LLMs), we’ve seen incredible feats of text generation, translation, and conversation. However, even the most powerful LLMs have limitations. They can sometimes “hallucinate” – producing plausible but incorrect information – or lack knowledge about events that occurred after their training data was collected. ...
Self-attention from scratch
Attention: Attention is one of the most talked about thing which became popular after the paper Attention is all you need. To talk about the high overview of attention, it is all about the values that gives importance to some of the part than others in this case. We will try our hands on attempt to code self attention from scratch today. Before starting, lets take a step back and understand how attention comes into place at all. ...
Implement LoadBalancing Algorithms using Python (Flask)
What is a Load Balancer? A load balancer is a critical component in distributed systems, responsible for distributing incoming requests across multiple servers to ensure high availability, reliability, and optimal performance. Load balancing can generally be categorized into two types: Path-based load balancing: Routes requests to different servers based on the request path. Application-based load balancing: Routes requests based on specific application logic, such as resource utilizaion or round-robin. In this post, we will focus on application-level load balancing and build one from scratch. To simplify the process, we’ll use a Flask web server as the application backend. ...
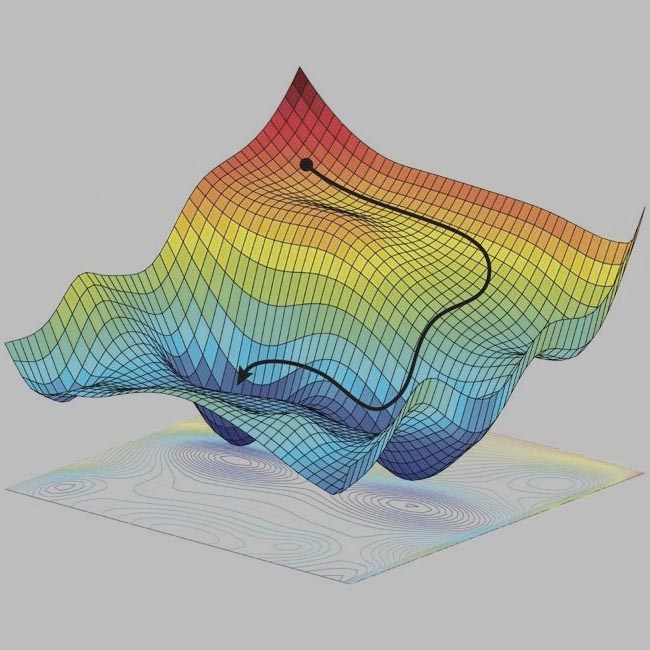
Optimization in Deep Learning
Optimizers are essential components of machine learning algorithms, responsible for adjusting the parameters of a model to minimize the loss function. A loss function measures how well the model’s predictions match the true values, and the optimizer helps find the parameters (weights) that minimize this loss. Essentially, the optimizer guides the model to find the optimal set of weights that result in the best performance. In this blog post, we will dive into the basics of some popular optimizers used in machine learning: Stochastic Gradient Descent (SGD), SGD with Momentum, and Adam. We will also visualize how each of these optimizers performs in finding the minimum of a given loss curve. ...
Initialization in Deep Learning
When training a neural network, after defining the model architecture, a crucial step is to properly initialize the weights. This initialization is essential to achieve stable and efficient training. Proper weight initialization helps prevent issues such as exploding or vanishing gradients, which can significantly hinder the learning process. It turns out that if you do it wrong, it can lead to exploding or vanishing weights and gradients. That means that either the weights of the model explode to infinity, or they vanish to 0 (literally, because computers can’t represent infinitely accurate floating point numbers), which make training deep neural networks very challenging. ...
Why Sigmoid Fails in Deep Neural Network?
Deep neural networks rely on the backpropagation algorithm to train effectively. A crucial component of backpropagation is the calculation of gradients, which dictate how much the weights in the network should be updated. However, when the sigmoid activation function is used in hidden layers, it can lead to the vanishing gradient problem. In this post, we’ll focus on how gradients are calculated and why sigmoid makes them vanish in deep networks. ...
Understanding Transformers in Machine Learning
Introduction Transformers have revolutionized the field of machine learning, particularly in the domain of Natural Language Processing (NLP). Originally introduced in the paper “Attention Is All You Need” by Vaswani et al. in 2017, transformers have become the backbone of many state-of-the-art models, including BERT, GPT, and T5. In this blog, we will explore the basics of transformers, how they work, and why they have become so popular in recent years. ...