The Roman Nepali Embedding Problem
I spelled the same Nepali word four different ways and asked four open-source embedding models whether the spellings meant the same thing. The model with the prettiest-looking cosine gap wasn’t the one that actually worked — and a twenty-line preprocessing script beat all four of them without touching a single weight.
This post is a small experiment with a strong conclusion: if you are shipping NLP for Nepali users today, the best thing you can do is not a bigger model — it’s a regex.
Why this bugs me
Most Nepali text on the internet is not in Devanagari. It’s typed in Roman script, on English keyboards, with no agreed-upon rules. So the same word gets written six different ways depending on who’s typing:
- हुन्छ (“is / happens”) →
hunchha,hunxa,huncha,hunch - भन्छ (“says”) →
bhanchha,vanchha,bhanxa,vanxa - काम (“work”) →
kamorkaam - त्यो (“that”) →
tyoorthyo
There’s a convention where people use “x” to stand for छ, which is borrowed from nobody — it just happened. There’s the v/bh confusion for भ because English readers can’t tell the difference anyway. Vowel length is completely vibes. Aspirates are approximate. The whole thing is chaos by design.
This would be a curiosity except that almost every NLP feature a Nepali user touches goes through an embedding model. Search pulls nearest neighbours. RAG retrieves passages. Chatbots compute intent similarity. Classifiers mean-pool tokens. If the embedding model doesn’t know that hunxa and hunchha are the same word, the whole stack silently returns wrong results to Nepali users, and nobody gets paged, because the metric everyone optimizes is English.
I wanted to measure how bad it actually is, and whether there’s a cheap fix before reaching for fine-tuning.
Setting it up
Before touching any code, I had to decide three things: which words to test, which models to test, and what “works” means.
The words. I hand-curated 20 variant groups, each containing a single Nepali word written 2–4 different Roman ways, plus the Devanagari ground truth. The 20 groups cover five specific ambiguity categories, because “spelling varies” is too vague — I wanted to see which kind of variation each model struggles with. The categories:
chha / xa / ch— the छ soundv / bh— the भ sound- vowel length —
avsaa,ivsii - aspirate —
thvst,khvsk - schwa — trailing
akept or dropped
Twenty groups is small. It’s also the right size for a first-pass probe: you can finish it in a day, look at every result personally, and catch any category where the signal is weird before you scale. If the findings hold on 20, you build the 500-group benchmark next. If they don’t, you just saved yourself a week.
The models. I picked four open-source multilingual models that are actually deployed in production today:
| Model | Dim | Why it’s on the list |
|---|---|---|
sentence-transformers/LaBSE |
768 | the cross-lingual default since 2020 |
intfloat/multilingual-e5-base |
768 | current go-to general retriever |
intfloat/multilingual-e5-small |
384 | e5’s small+fast sibling |
paraphrase-multilingual-MiniLM-L12 |
384 | old baseline still in a lot of code |
No proprietary APIs. I want anyone reading this to be able to reproduce it on a laptop.
What “works” means. This is the part that took the most thought. The obvious metric is “are same-word variants close in embedding space?” — but “close” can mean two different things, and they don’t agree.
- Cohesion: average cosine similarity between pairs of variants within a word group.
- Separation: average cosine similarity between pairs of variants across different word groups.
- Discrimination gap: cohesion minus separation — how much closer same-word pairs are than random pairs.
- Retrieval P: the actually-useful metric. For each variant, treat it as a search query; measure what fraction of its top-k neighbours (k = group size − 1) are its real group-mates.
And one bonus:
- Devanagari alignment: for each Roman variant, its cosine similarity to its Devanagari ground truth — does the model realise
hunxaand हुन्छ are the same thing?
Cohesion and separation summarise means. Retrieval P measures what happens when you actually use the model. Spoiler: they don’t always rank models the same way, and the reason is instructive.
Result 1 — the headline that almost tricked me
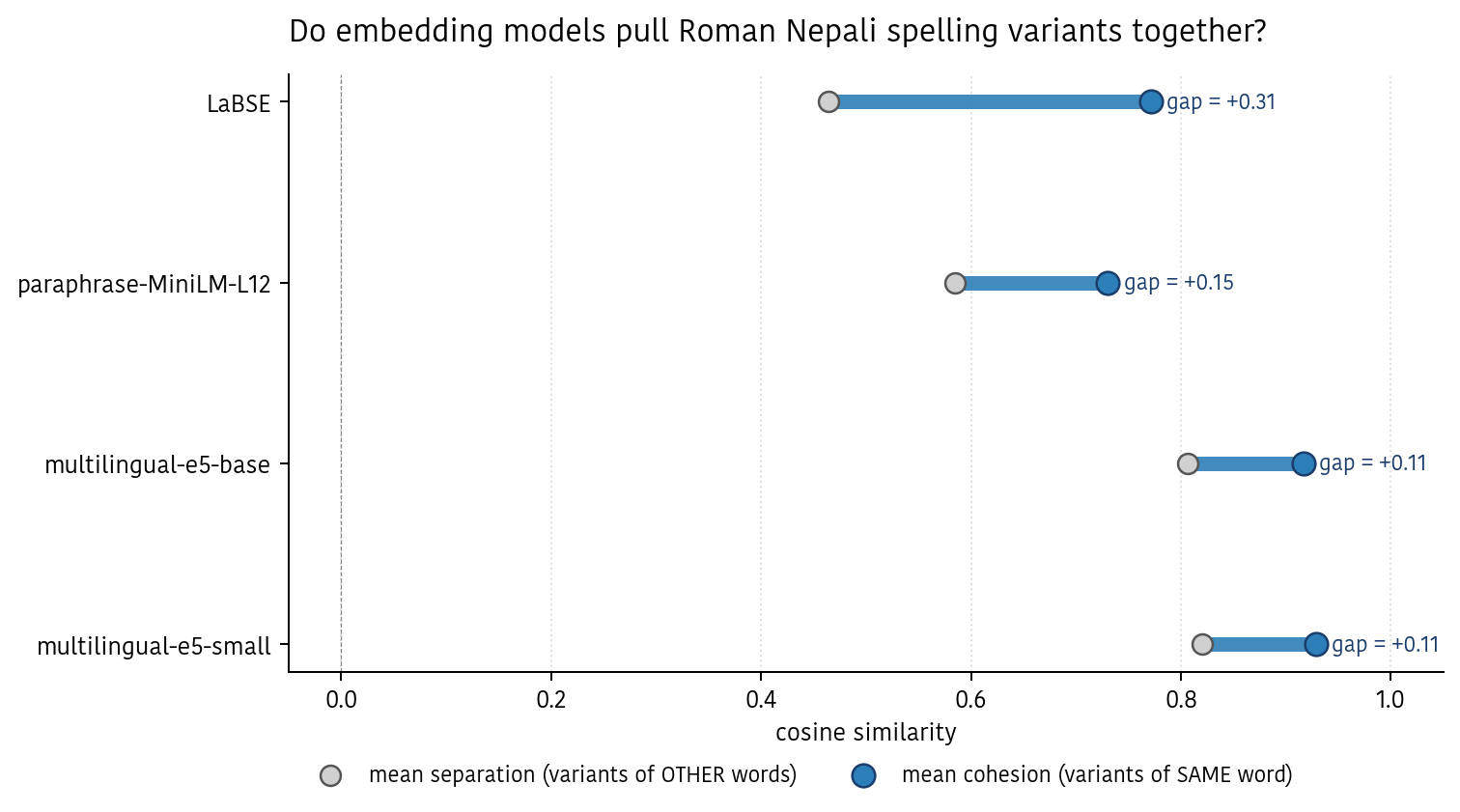
Here’s how to read this chart. Each row is one model. The gray dot is the model’s separation — the average cosine similarity between variants of completely unrelated words. Treat that as the model’s “random baseline” for this dataset. The blue dot is the model’s cohesion — the average similarity for pairs of variants that are actually spellings of the same word. The blue bar is the gap between them.
A model that understands Roman Nepali variants should pull same-word pairs far to the right of random pairs. The wider the blue bar, the better, in theory.
By that standard, LaBSE looks great: its variants sit 0.31 cosine points tighter than random pairs. The two e5 models look almost flat — a tiny 0.10–0.11 gap.
But here’s the actual retrieval performance:
| Model | cohesion | separation | retrieval P | Devanagari |
|---|---|---|---|---|
| LaBSE | 0.77 | 0.47 | 0.70 | 0.49 |
| multilingual-e5-small | 0.93 | 0.82 | 0.82 | 0.84 |
| multilingual-e5-base | 0.92 | 0.81 | 0.79 | 0.82 |
| paraphrase-MiniLM-L12 | 0.73 | 0.59 | 0.38 | 0.57 |
The model with the widest gap loses on top-k retrieval. The model with the smallest gap wins. What’s going on?
Result 2 — why the gap lies
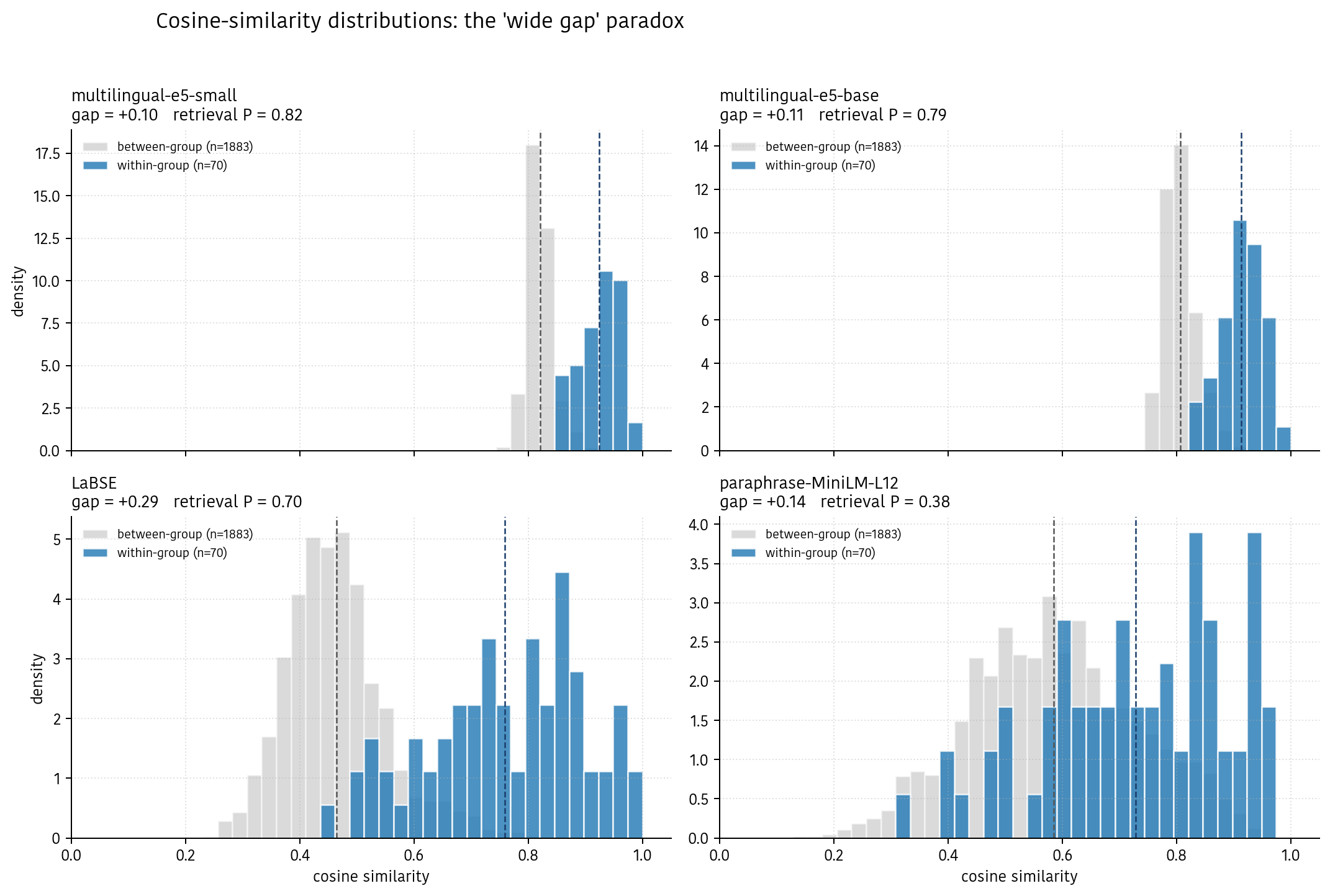
I’m showing you distributions, not just means. Each panel is one model. The blue histogram is every cosine similarity between two variants of the same word — for our 20 groups that’s 70 pairs. The gray histogram is every cosine similarity between variants of different words — 1883 pairs. The dashed lines mark the two means we computed above.
Here’s the intuition that made everything click for me.
Think of same-word pairs and different-word pairs as two clouds. For a model to be useful at retrieval, the blue cloud has to sit cleanly above the gray cloud — not just have a higher average. If the clouds overlap, top-k gets contaminated: some random pair of unrelated words ranks higher than a genuine same-word pair, and it creeps into your search results.
Look at e5-small (top left). Everything is jammed into a narrow window between 0.7 and 1.0. The gap between means is tiny. But the blue histogram sits cleanly above the gray histogram — almost no overlap. Ordering is preserved inside the narrow cone, which is all retrieval needs.
Now LaBSE (bottom left). Big gap. Distributions spread across the full 0.0–1.0 range. Look at the blue histogram’s left tail — a meaningful chunk of same-word pairs have cosine similarity below 0.5, dipping into the gray cloud. For those pairs, random unrelated words rank above their true group-mates. That’s why retrieval P drops to 0.70 despite the impressive-looking mean gap.
And MiniLM (bottom right) is the extreme case: the two clouds are braided together. The mean gap exists but is basically noise. Retrieval collapses to 0.38 — little better than chance on this task.
The lesson: means lie; distributions tell the truth. If someone reports a “discrimination score” or “gap” without showing you the distribution, they’re not necessarily wrong, but they’re answering a different question than retrieval asks. I almost shipped “LaBSE is best” after looking at the first chart. The distribution plot is what saved me.
Result 3 — the ambiguity that breaks every model
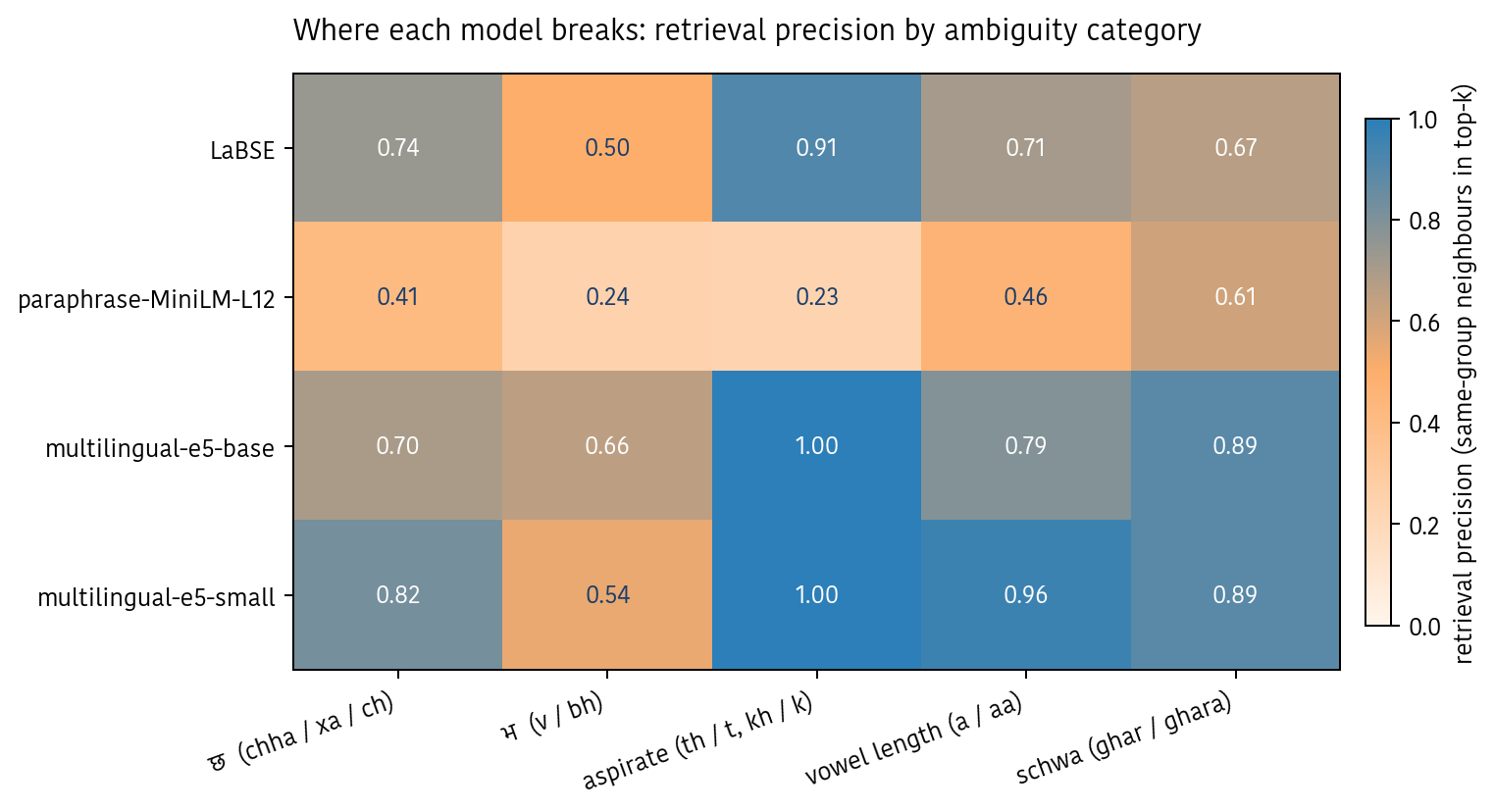
Once you look inside a model and break retrieval down by category, one pattern shows up across all four models: some spelling confusions are easy, some are universally hard.
Easy: aspirate swaps — tyo/thyo, khana/khaana, phohor/fohor. Both e5 models hit 1.00 retrieval P here. These variants differ by at most one character, and subword tokenizers are good at that. The token khana and the token khaana share most of their pieces.
Hard, for everyone: v/bh confusion. LaBSE 0.50, e5-small 0.54, e5-base 0.66, MiniLM 0.24. vayo vs bhayo is not a one-character swap — it’s a whole consonant replaced by a digraph. The tokenizer sees v as a distinct token from bh, and there’s no signal from Nepali’s written corpus teaching it they’re the same sound.
Second-worst: chha / xa / ch. The “x” convention is so rare outside Nepali internet that Latin-trained tokenizers effectively treat xa as a foreign byte sequence with no near neighbours.
A useful one-line mental model: vowel edits are cheap; consonant swaps are expensive. If your Nepali NLP stack is failing, I’d bet the queries that fail disproportionately involve a v/bh or xa/chha swap.
Result 4 — what the embedding space actually looks like

Numbers are one thing; seeing the embedding space is another. I ran a 2D t-SNE over every Roman variant from the e5-small embeddings and laid it out as a constellation — the Devanagari ground truth sits in the centre of each “flower,” with every Roman spelling of that word arranged on a petal around it. Each group gets its own colour. Petal positions within a flower are decorative (the real within-group distances are tiny); distances between flowers are what the t-SNE is showing you.
You can verify the finding by eye. The हुन्छ family (hunchha/hunxa/huncha/hunch) sits clearly on its own. Similarly for पुग्छ, भन्छ. So far so good.
But the messy parts are visible too. भात (bhaat/vat) and भाइ (bhai/vai) sit almost on top of each other — which is honest, because they look nearly identical in Roman. छोरा (chhora/xora/chora) is pulled toward छ (chha/xa/cha) because the shared “x”-token is weighted heavily. And राम्रो (“good”) ends up floating next to no one in particular.
This is the most honest picture I can show of where current models stand: mostly correct, sometimes confused, always at the mercy of the tokenizer. Which sets up the fix.
Result 5 — a regex beats all four models
If the problem is that hunxa and hunchha look like totally different strings to a Latin tokenizer, the simplest fix is to stop feeding the model two different strings. Normalise the Roman variants to a canonical form before embedding.
I wrote a 20-line rule-based normaliser — no ML, just substitution rules that match Nepali spelling conventions:
s = re.sub(r"xa", "chha", s) # hunxa -> hunchha
s = re.sub(r"x", "chh", s) # xora -> chhora
s = s.replace("v", "bh") # vayo -> bhayo
s = s.replace("f", "ph") # fohor -> phohor
s = re.sub(r"a{2,}", "a", s) # raamro -> ramro
s = re.sub(r"i{2,}", "i", s) # timii -> timi
s = re.sub(r"e{2,}", "i", s) # timee -> timi
s = re.sub(r"o{2,}", "u", s) # koora -> kura
# ...geminate nasals collapsed. I deliberately do NOT touch aspirates —
# 'thaha' (know) and 'taha' aren't the same word, just sloppy spelling.
Each rule encodes a convention every Nepali speaker already knows. “v” is just how people write भ when they learned English alphabet rules. “xa” is just how people write छ. I’m not teaching the model anything new — I’m just removing the encoding noise before the model sees the text.
Then I re-embedded all 63 variants after normalisation and ran the same eval. Here’s what happened:
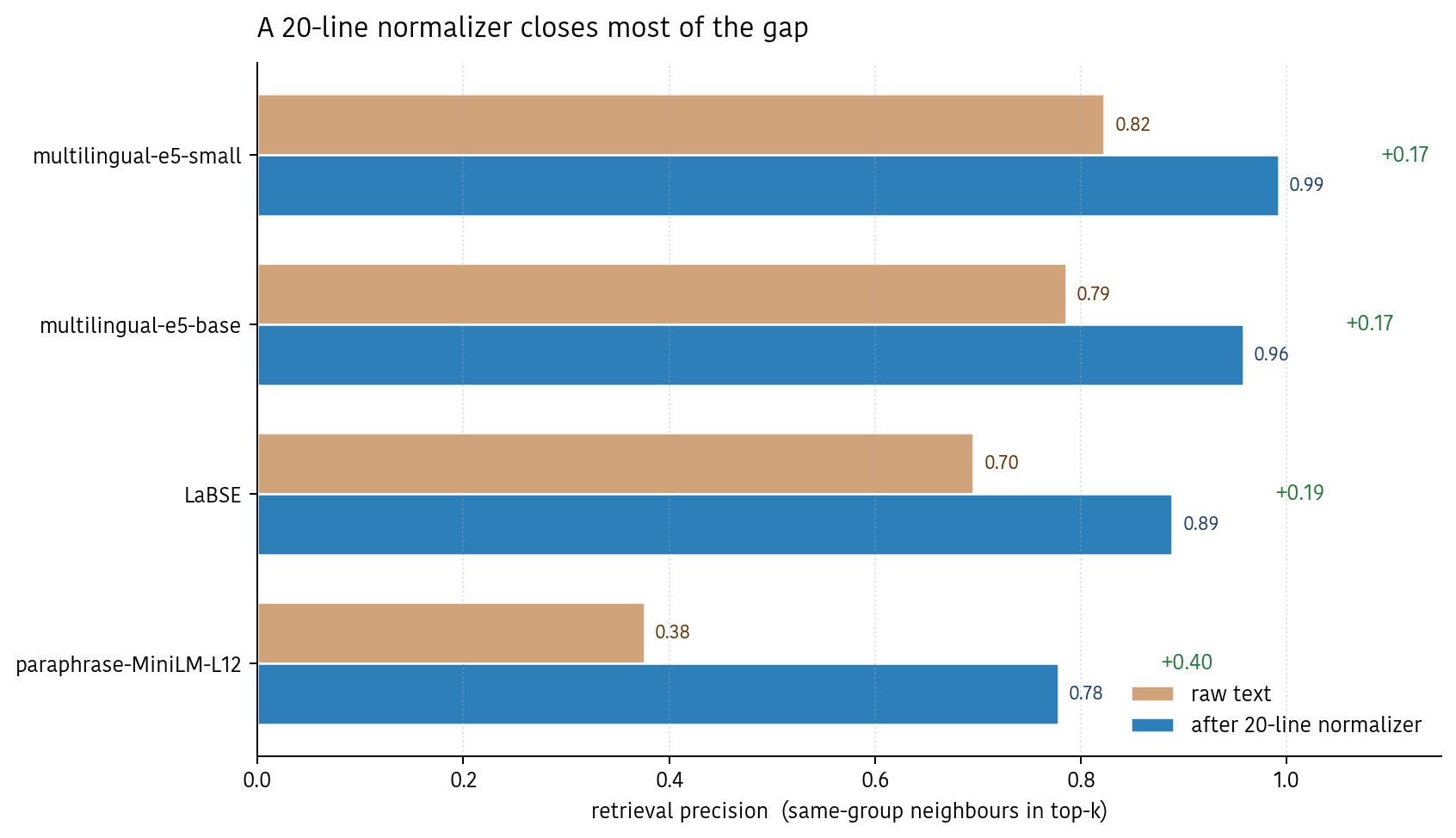
- multilingual-e5-small: 0.82 → 0.99. Near-perfect retrieval.
- multilingual-e5-base: 0.79 → 0.96.
- LaBSE: 0.70 → 0.89.
- paraphrase-MiniLM-L12: 0.38 → 0.78 — more than doubles.
Every model jumps. Cohesion rises 0.14–0.19 points across the board; separation barely moves. That’s important: it means the normaliser is fixing the right thing. It’s making same-word variants more similar to each other without also making unrelated words more similar to each other. The problem was encoding noise, and removing encoding noise tightens up exactly what we wanted tightened.
This is the most surprising finding of the experiment: on this task, deterministic preprocessing is a strictly better use of engineering time than picking a bigger embedding model. A 20-line regex takes an unusable model (MiniLM) to decent and a decent model (e5-small) to nearly perfect, at zero inference cost.
So what
Three practical recommendations for anyone building Nepali NLP today:
- If you’re using MiniLM, stop. Even after normalisation it’s the weakest model tested, and without normalisation it’s majority wrong.
- multilingual-e5-small + a rule-based normaliser is the free-tier best. 0.99 retrieval P on this probe, 384-dim, CPU-friendly, and strong Devanagari alignment (0.84) out of the box for cross-script queries.
- Don’t trust discrimination gap as a single number. Always plot the distribution before deciding which model to ship. The gap is the means; retrieval depends on the overlap.
What’s next
- Scale the dataset. Twenty groups is a first probe. A serious benchmark needs a few hundred groups harvested from real Nepali social media — because actual users invent spellings that curated lists miss.
- Try a contrastive fine-tune of e5-small on variant pairs, and compare to “vanilla e5-small + normaliser”. If the fine-tune doesn’t beat a regex, we’ve learned something useful about where ML is and isn’t worth it.
- Ship the normaliser. Honestly, the single most valuable output of this experiment isn’t any chart — it’s
scripts/normalize.py, which is maybe 500 bytes of Python.
The bigger picture: no embedding model in wide use was trained with Roman Nepali in mind, and it shows up in every metric. But the right next move isn’t a bigger model. It’s better preprocessing and better evaluation data — both of which are measured in days, not GPUs. The opportunity is wide open because nobody has done the boring work.
Data: 20 hand-curated variant groups (63 Roman spellings + 20 Devanagari), 5 ambiguity categories. GitHub repo: https://github.com/paudelanil/anil-blog-lab/tree/main/roman-nepali-embedding. Code to reproduce: scripts/embed.py, scripts/evaluate.py, scripts/normalize.py, scripts/visualize.py.